Before starting with the technical stuff let’s me ask you a question :

What do you see on this image ?
A human : will see a guy laughing, drinking some wine wearing a tuxedo with a flower on it, if this particular human have the context he could tell you that this is leonardo dicapro playing in django unchained and/or if you have the meta that this is also a famous based meme.
A Machine : will not be able to process this exact same photo
A machine cannot interpret the same way as a human can interpret a photo or know defacto the context of it. That when Vector Embedding come in action.
Vector embedding is a machine learning and natural language processing technique that allows us to represent complex data, such as image/words or sentences, in a mathematical form and in this little article we’ll showcasing the concept, it’s application and some underlying mechanisms that make it an essential tool in data science and the role it play in our actual world.
1 – How Vector Embeddings works
The process of vector embedding :
INPUT —> Embedding Model —> [0.2, -0.4 , 7.2, 19.5, 22.3]
Let’s refer to our example above the image would be the input and once processed to our embedding model it will transform our image to a vector (a numerical representation of number sequences).
if you process several image of leonardo dicaprio, and completely other stuff such as cat, transportation and computer you will end up with a vector embedding like so :
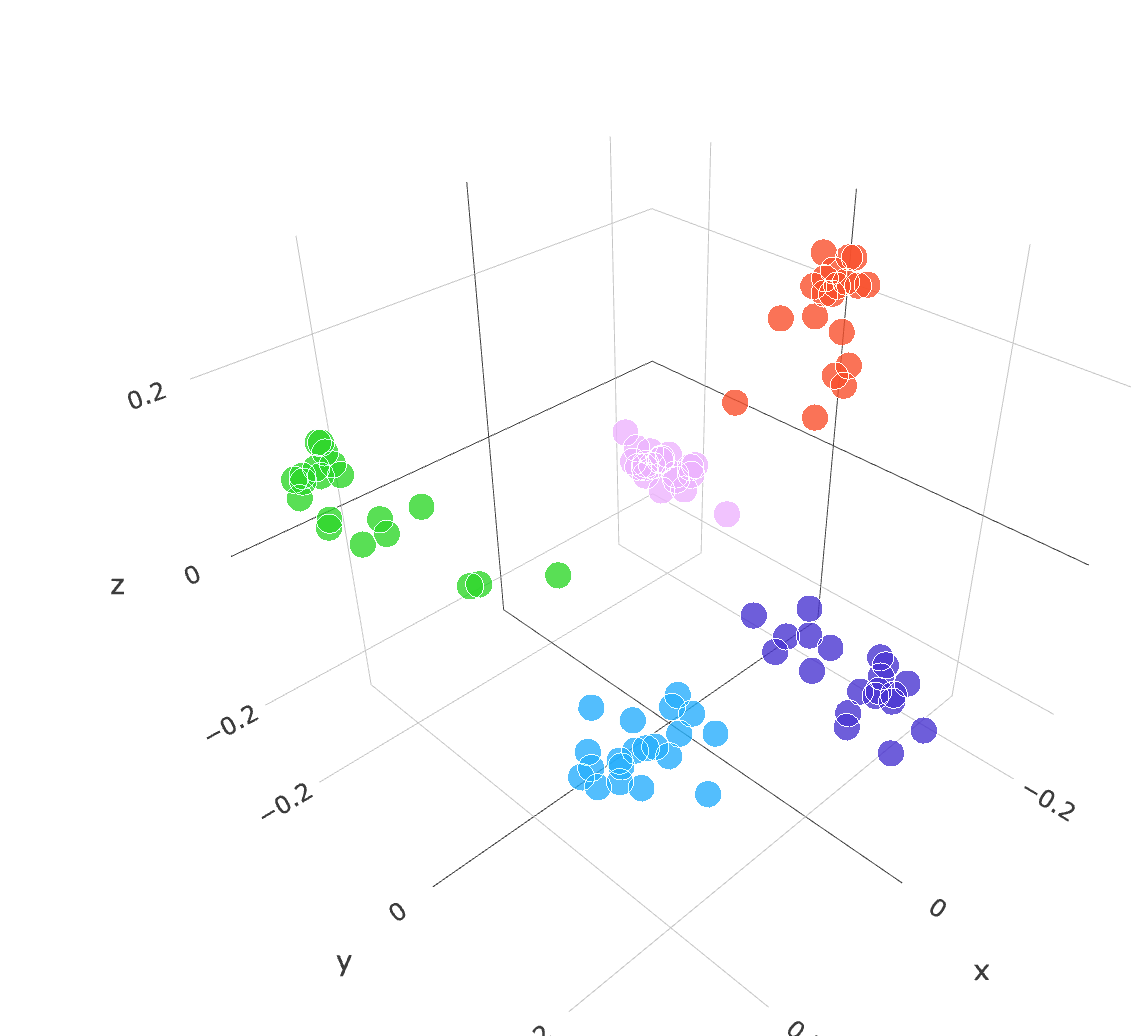
where each image category will be classify according the relationship, or contextual information between them for example the face of leonardo dicaprio with the pink dot and the cat with the blue dot …
The embedding model will be able to give similar vector to image that have similarities with other :
Dicaprio face 1 = [0.2, -0.4 , 7.2, 19.5, 22.3] —— Cat 1 = [15.2, -25.4 , 17.2, 11.5, 32.3]
Dicaprio face 2 = [0.9, -1.4 , 8.2, 21.5, 19.3] —— Cat 2 = [15.8, -23.4 , 18.2, 9.5, 28.2]
from the vector above you can clearly see that Dicaprio face vector are closer to each other than it is from the cat vector
Embedding allow us to represent really complex data in a way that is easy for machine to understand, learn and interact with us in a more meaningfull way
Those vector are then stored into a vector database
2 – Why a Vector Database
Main advantage of vector database over traditional one is that vector represent point into a multidimensional space
in the case of ML Engineering or NLPT those database are the way to go because it offers a number of advantage such as :
- Faster similarity search
- better scalability
- Easier Integration with ML Framework
Building on the concept of word embeddings, this section focuses on representing entire sentences or phrases as vectors. Methods such as Doc2Vec and Universal Sentence Encoder have gained prominence in this domain. We’ll examine how these techniques address the challenge of capturing the meaning and context of longer sequences of words.
3 – Real World Application of Vector Embedding
Have you ever bought shoes on a website, lets say a stan smith and see that the website recommend you white shoes similar to the stan smith you bought that’s because the vector of those 2 shoes a quite similar and if you bought one why would you not buy something similar ?
Same process occur on social media like twitter that will recommend you content of user based on their behavior and point of interest that look like yours.
That’s it for today hope you like this little article and see you next time